浏览【23956】 2021-09-17 22:30:00

伴随装备制造业的不断革新,产生了自主维修、状态检修等新型设备健康管理模式,极大地推进了设备健康管理的创新与发展。而这些新模式的基础和核心就是故障预测与健康管理(Prognostics and Health Management, PHM)技术。

一、什么是PHM?
PHM技术是指釆用传感器信息、专家知识及维修保障信息,借助各种智能算法与推理模型进行设备运行状态的监测、预测、判别以及管理,实现低虚警率的故障检测与隔离,解决传统维修过程中存在的“维修不足”及“维修过剩”等问题,有效提高设备的可用性、减少保障费用,并最终达到设备状态的智能维护及智能任务规划的目的。
PHM 技术将设备管理与运维从事后维修、计划检修推向了状态检修阶段,提供故障从发现到解决全过程一体化方案。核心功能包括:状态监测、故障预测、原因分析、策略匹配、计划保障、维修辅助、维修保障等。
二、统计分析和机器学习在PHM的应用
为保障系统功能的精准性与高效性,以统计分析和机器学习等大数据挖掘技术为代表的故障预测与诊断方法逐渐被应用于PHM领域,快速推进了PHM 技术的发展。
相关技术和方法包括统计分析、概率推理、分类预测、综合评价等,已经在实时状态监控、故障判别、健康预测及辅助决策等多个场景得到应用和落地,并取得了非常不错的效果。
1、实现设备的多层级监控预警
监控状态是设备健康管理体系中重要的一环,设备状态监测需要对设备运行参数、运行状态等数据进行实时监控和预报警推送。
目前,设备的安全预警阈值更多是依赖人工经验对设备当前监控指标设定安全警戒线,缺乏科学的依据,容易出现由于预警值设定较低导致虚警率过高问题,或是因为设置预警阈值过高,导致报警时就已经发生了不可逆的故障。
基于这种情况,企业期望在传统经验预警的基础上加入更加科学的数据分析方法,实现多级预警。
基于统计分析实现科学的阈值划分
通常设备出厂设定的阈值叫做其安全预警,也是多级预警体系中的一级预警。在此基础上,可以通过数据分析的方法来构建二级预警,二级预警的解决思路是运用异常检测的方法,对历史数据进行统计分析,形成静态或动态工况的参数阈值。
此类方法常见的有基于箱线图的异常检测、基于分位数的异常检测、基于Z-Score的异常检测以及基于拉依达准则的异常检测等。在实际使用过程中,可以通过模型的不断更新来生成动态参数阈值,这样做的好处是使得参数更加符合设备当前的运行状况。
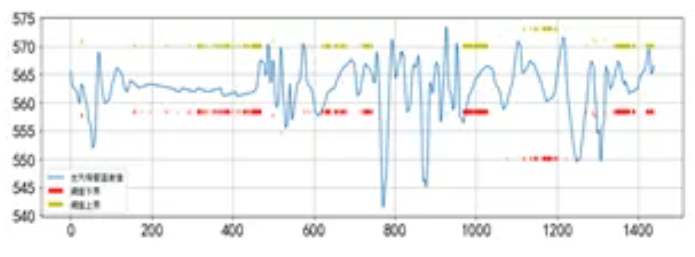
比如,我们在汽轮机设备监测预警过程中,针对主汽母管温度阈值的确定,使用了基于箱线图的异常检测方法。如下图左侧是箱型图方法,右侧是基于这种方法得出的阈值。与设备根据经验确定的一级预警值共同提供预警服务,图中不连续的点是因为并未对全部的工况进行划分,这主要是考虑到数据量的因素。
基于回归预测实现异常提前发现
设备状态监测指标为运维人员提供当前的设备运行情况,但如果设备出现状态异常时,比如已经或即将达到设备故障的临界点,则留给运维人员的维修时间较少,因此,需要提前对设备的运行状态进行异常预警。
关于设备运行状态的指标预警,主要是对各个运行指标进行预测。其中,不但要考虑指标自身变化,还需要考虑其它指标变化对该指标的影响。
针对这类问题,常用回归预测方法进行建模预测,包括线性回归、岭回归、SVR、梯度提升回归树、XGboost回归等等。而关于回归算法的选择,可以尝试多种算法进行预测与对比,并从中选取误差较小的一种算法。当然,在指标选择时还会运用到相关分析、方差分析等方法进行指标选取。
以汽轮机上“低温省煤器入口温度”预测为例,通过相关指标分析确定影响该指标的因素有发电机功率、锅炉给水流量、主汽门蒸汽压力、冷段再热母管蒸汽压力。同时,确定上述指标与目标指标之间的时间差,并基于此来构造200多个指标,然后运用线性回归、岭回归、SVM回归、XGBoost回归四种方法进行建模预测,其中XGBoost回归效果最佳。
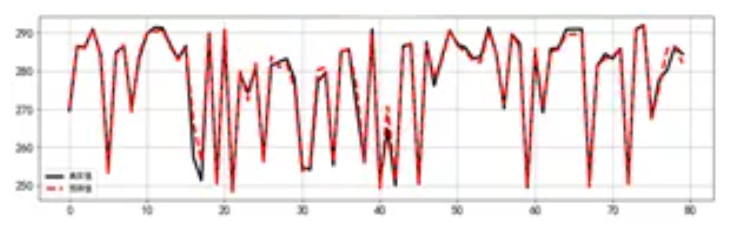
值得一提的是,随着预测时间长度的变化,预测准确度评判指标R方有一个衰退趋势,在这组数据预测中,预测近1分钟的数据R方为0.97,10分钟的值R方衰退到0.91,30分钟R方衰退到0.78。在实际使用中需要根据业务需要确定预测时间范围,同时,如何减缓衰退也是模型要改善的目标之一。
基于历史趋势拟合实现异常预警
对于结构相对简单,或可变参数相对较少的设备,由于其指标之间相互没有影响,在进行故障预警多围绕单个指标进行分析。这里,可以根据历史故障发生前后指标的变化进行趋势的拟合,再以拟合好的公式对新的数据进行判断,提前发现异常。
比如,在判断动车上牵引变流器冷却系统滤网是否堵塞的故障时,冷却系统油温/水温变化就是一个非常关键的指标,我们可以对滤网清理后到堵塞前这段时间的温度变化进行拟合。它们之间的关系可以是线性也可以是非线性的,根据实际情况进行选择,但注意在选取数据的时候一定是要选择在相同工况下的数据,同时对于不同次故障前指标的变化需要进行无量纲处理。
进一步地,对两次滤网堵塞情况(一次轻微堵塞、一次严重堵塞)在上次清理到堵塞前的数据进行对齐处理,通过对指标标准化后,选择指数拟合、logistic拟合、二次拟合、增长拟合等多种方法进行拟合,然后通过误差分析来选择最好的一种拟合算法。
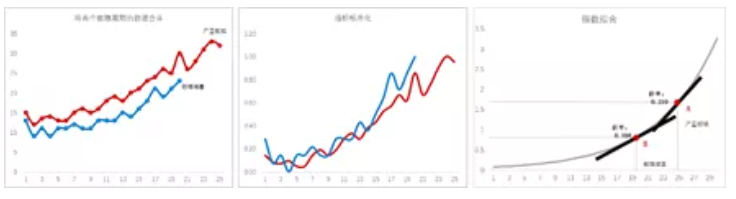
在模型拟合好之后,再将轻微堵塞和严重堵塞两种情况分别在曲线上进行标注,这时轻微堵塞的温度增长率为0.108,严重堵塞的增长率达到0.21,在实际应用中可以在列车运行过程中对每天的温度与上一天温度的变化进行预警,而预警值要在轻微堵塞之前,比如0.09。
2、实现智能化故障诊断
前面提到针对不同指标/测点的监测和分析,可以获悉单个指标/测点当前是否超出范围,以及未来一段时间的状况。
在实际的应用过程中,部分单个测点可以直接表征一类故障,但更多时候,一个故障的发生可能会引发多个测点表现异常。而且,不同的故障可能导致的异常程度不一致。
那么,如何根据这些异常测点精准地定位到具体的故障类型呢?根据应用场景的不同、设备的不同、采集数据类型的不同,有不同的故障诊断方法。
基于多指标异常检测实现故障预警
前面讲的都是基于单个指标通过阈值进行异常预警,在实际应用中,我们会发现一种故障对应的异常点可能会出现多个,且多个部位之间有连锁反应,其中的某一个部位异常不足以说明问题,需要结合多个部位的数据综合判断才能给出明确的答案。
针对这类问题可以选择异常检测方法,异常检测方法一般分为四类:基于统计的Robust Covariance、基于密度的局部离群点检测LOF、基于划分的Isolation Forest以及基于分类的One-class SVM。
比如,对于列车齿轮箱温度故障,仅用一个轴端温度不足以说明故障的产生,还需要结合同侧温差和温升等数据进行判断。这时,使用异常检测算法是一个不错的选择。通过对比不同算法检测出异常的准确率和召回率,可以实现多种不同算法之间的比较,以此来确定哪种算法最优。
基于分类预测实现故障诊断
对于复杂设备,由于设备故障的产生是由多个因素综合导致的,在这种情况下,使用传统方法进行判断的准确性并不高,还需要综合考虑各方面的因素进行预测。同时,由于设备故障类型多样,还需要对不同的故障分别进行分析。在这方面,基于分类的机器学习方法得到了较为广泛的应用。常用的分类算法包括:决策树算法、随机森林分类、梯度提升树分类、神经网络、SVM分类、贝叶斯网络分类、Xgboost分类等。
比如,在针对油浸式变压器进行故障的时候,故障的类型有局部放电故障、高能放电故障、低温过热故障、高温过热故障、油道堵塞故障、绝缘老化故障等等。我们提取设备运行过程中的油中溶解气体含量指标,包括c2h6、co2、n2、o2、c2h4、ch4、co、h2、c2h2,将故障作为目标指标进行分类模型构建。我们在实际中使用了梯度提升树算法、支持向量机算法和随机森林算法,并取得了不错的效果。
基于综合评价实现设备健康评估
在实际的生产中,大型设备一般包含多个关键部件,想要了解整体设备的健康状况,可以使用综合评价方法进行设备健康评估。此方法是基于业务理解及设备构造分析,对设备关键部件所对应的评价指标进行梳理,从而构建综合评价模型,并对设备及其各部位进行全方位的评价。该方法的好处在于,一方面,可以对设备进行综合监控、及时预警;另一方面,可对设备发生异常现象的情况进行原因追溯,指导维护人员快速定位设备问题。
设备健康状态评估一般使用的指标包含几个方面:设备上监测指标、设备部件的消耗情况、设备生产过程中的生产效率、产品质量、物耗状态等。
例如,在对烟草生产过程中的某成型设备进行健康状况综合评价时,我们构建了“评价维度-评价要素-评价指标”三级综合评价体系,从设备效率表现指数、产品质量放心指数、设备物耗评价指数三个维度进行总体评价,每个维度下又分为若干评价要素,每个评价要素下分若干个评价指标,最终得到设备健康状况综合得分,发现设备综合得分降低后,可以快速追溯到是哪方面的原因导致的,便于企业运维人员快速维护。
基于性能劣化的寿命预测
由于观测设备全生命周期内的变化非常困难,因此这里说的寿命预测主要是针消耗类产品或对设备上的消耗件/周转件(如轮胎、轴承、刀具、电池、刹车片等),不考虑设备整体的剩余寿命。此类部件寿命预测多是通过历史数据发现部件在设备性能、生产效率、生产质量等方面的劣化趋势,然后通过曲线拟合的方式,构建部件全生命周期内的设备性能/效率/质量趋势曲线,进而通过当前部件的性能劣化表现,反推其处在生命周期的具体阶段。
3、提高故障原因/策略的发现效率
传统设备故障诊断主要依靠人工经验进行原因分析和策略匹配,企业在历史的设备故障诊断过程中也沉淀了大量的原因诊断及策略匹配的知识,那么如何将这些知识进行合理规整及高效利用?目前,部分企业已经建立了故障相关的知识库并加以利用,而机器学习在其中发挥的作用:一是在构建知识库的过程中,提高知识库的构建效率;二是在知识库的使用过程中,提高使用的效率。这里,主要会用到的文本分类、聚类及相似度等方法。
基于聚类分析实现知识库快速构建
在设备故障诊断过程中,诊断知识库的构建是非常重要的一个环节,它的结构内容合理与否直接影响着诊断效率,但这部分工作也是最难的,这是由于企业历史的故障原因、维护策略等数据大多都是人工填写,而企业在早期并没有建立一个统一的规范,从而导致整理现有的故障记录、构建故障知识体系的难度非常大。基于文本分析+聚类的方法能够很大程度上减少人工工作量,从而提高知识库构建的效率。
例如,在构建发动机故障知识库的过程中,涉及到对发动机故障知识进行分类。由于故障数据非常多,要想通过人工实现,工作量非常大。而通过文本分类的方法对所有故障进行分词,然后通过聚类的方式对所有故障进行划分,并根据划分的结果对每一类故障进行标注,这样就能够节省很多时间。
基于相似度计算实现故障原因/策略精准匹配
由于观测设备全生命周期内的变化非常困难,因此这里说的寿命预测主要是针消耗类产品或对设备上的消耗件/周转件(如轮胎、轴承、刀具、电池、刹车片等),不考虑设备整体的剩余寿命。此类部件寿命预测多是通过历史数据发现部件在设备性能、生产效率、生产质量等方面的劣化趋势,然后通过曲线拟合的方式,构建部件全生命周期内的设备性能/效率/质量趋势曲线,进而通过当前部件的性能劣化表现,反推其处在生命周期的具体阶段。
维修人员在设备故障定位及维修过程中,由于经验的缺乏可能会导致故障的排查和处理速度较慢,针对此类情况,企业会建立辅助排故系统来帮助维修人员快速的定位故障原因和匹配策略。具体来说,通过对问诊过程中获取的设备现象描述与故障知识库中现有的故障现象、原因进行匹配,发现与当前设备现象相似的故障,将历史原因及解决措施进行推荐,帮助用户快速解决问题。相似度计算的方法包括欧氏距离、皮尔逊相关系数、余弦相似度、广义Jaccard相似系数。
例如,对汽轮机设备进行辅助排故的过程中,通过数据的自动采集获取到设备当前运行状态数据,明确部分指标发生异常,但是无法定位到具体原因,这时可以通过对当前设备运行状态与历史发生的异常情况进行相似性计算来定位原因。
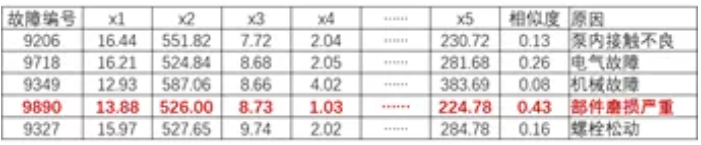
通过对设备当前运行状态与历史异常情况进行相似度分析,发现当前设备运行状况与历史编号为“9890”的异常情况相似度最高,对此我们可以将“9890”对应的故障原因、排查步骤、维修策略等历史知识推送给维修人员,提升维修效率。
三、结束语
本文介绍了几种常用的机器学习与统计分析方法在设备故障诊断中的应用,我们称之为基于数据驱动的故障诊断。在实际设备故障诊断过程中,除了使用数据驱动的方法,还需要结合设备机理知识、专家经验知识等对设备健康状况进行综合分析。
此外,在数据驱动的诊断过程中也会存在一些特殊的数据处理及分析方法,例如针对信号类数据(设备上的震动、声音、电流等)采用信号处理方法进行故障判断。当然,还有一些设备故障判断的方法,如曲线相似度法、历史数据包络算法、特征相似度法,受篇幅的限制,我们会在今后的文章中再跟大家详细分享。
随着企业对生产过程智能化要求的提高,设备健康管理将越来越受重视。同时,伴随数据采集的全面性,基于数据驱动的方法在故障诊断中发挥的作用将会越来越大。利用机器学习基本知识,探索/组合新的智能化模型,更加高效、准确的解决异常预警、故障发现、原因分析、策略匹配等设备运行维护过程中的问题,是企业数据分析人员的责任,是企业智能化必经之路。
 陕公网安备 61019002000171号
陕公网安备 61019002000171号

